前言
Hello,大家好啊!经过两个月的疯玩,现在临近期中考试,我又来沉淀了!最近对Python爬虫挺感兴趣,于是进行简单学习后搞了一个入门小项目,这次我将对淘宝网站的接口进行研究!
前提准备
- 模块安装:Requests、fake_useragent、execjs
- 目标网站:https://www.taobao.com
分析目标
初步分析
首先,打开淘宝官方网站,在搜索栏中输入关键字进行搜索,将进入我们即将分析的数据页面,在该网页可以看到商品的名称、价格、销售量等等各种数据信息,接下来我需要对这些数据进行采集。
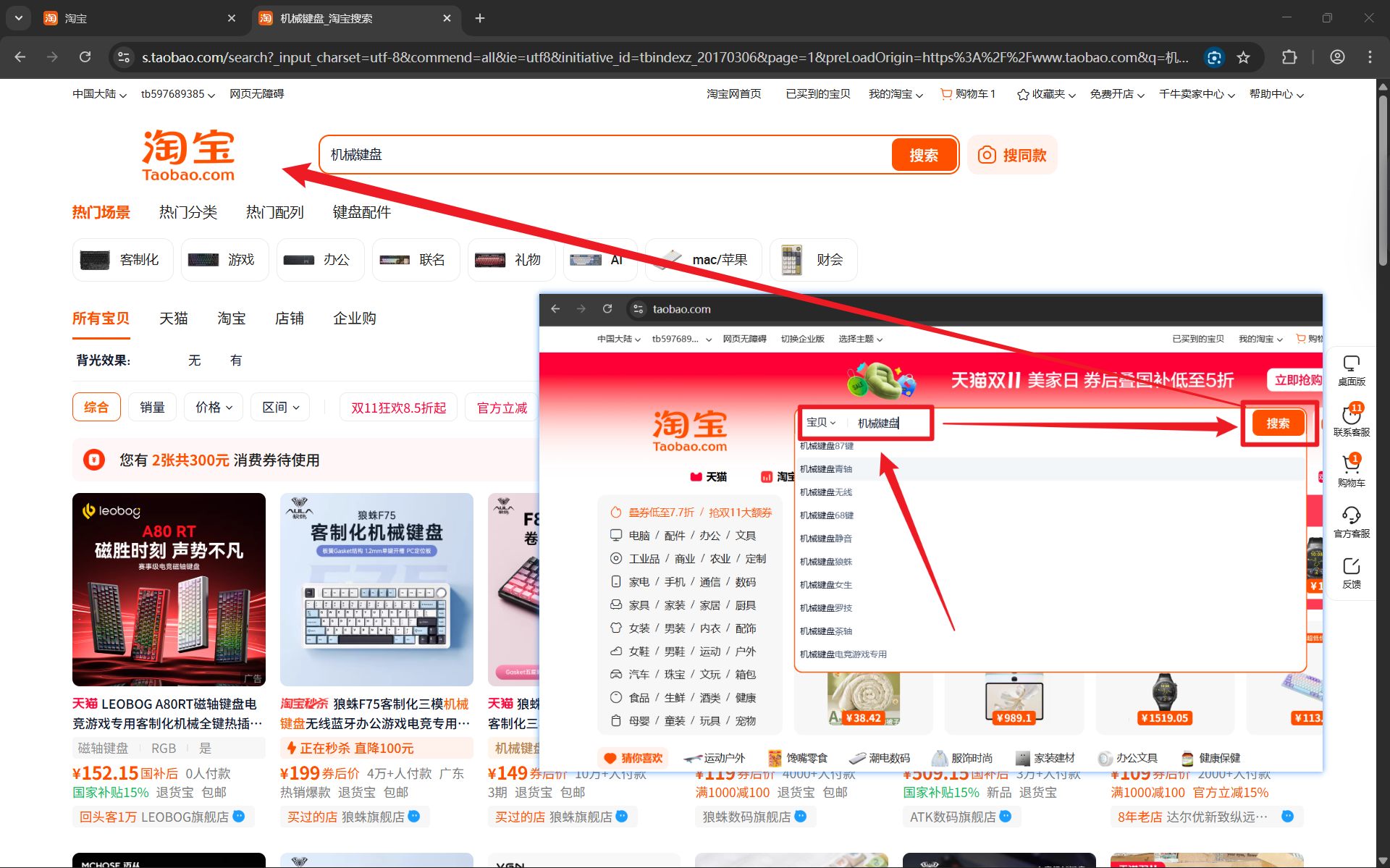
打开network工具,刷新网页对数据包进行抓取,在网页信息中任意找一个价格在network搜索栏中进行搜索,找到我们需要抓取的数据包。
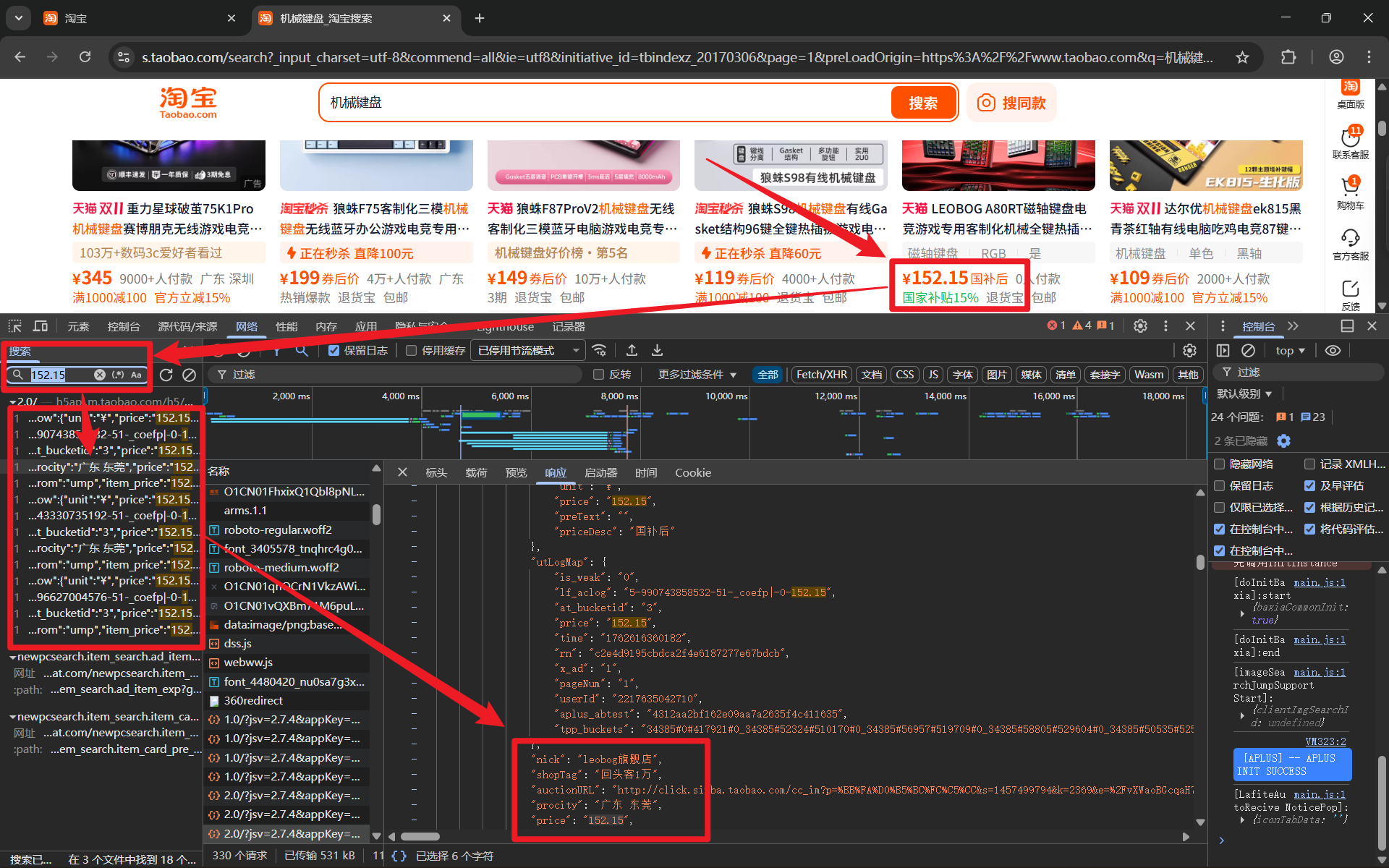
工具栏切换至 预览 面板,然后依次点开 data -> itemsArray,将发现我们所需的数据都在该位置,所以可以确定这个数据包就是接下来我所需要采集的目标。
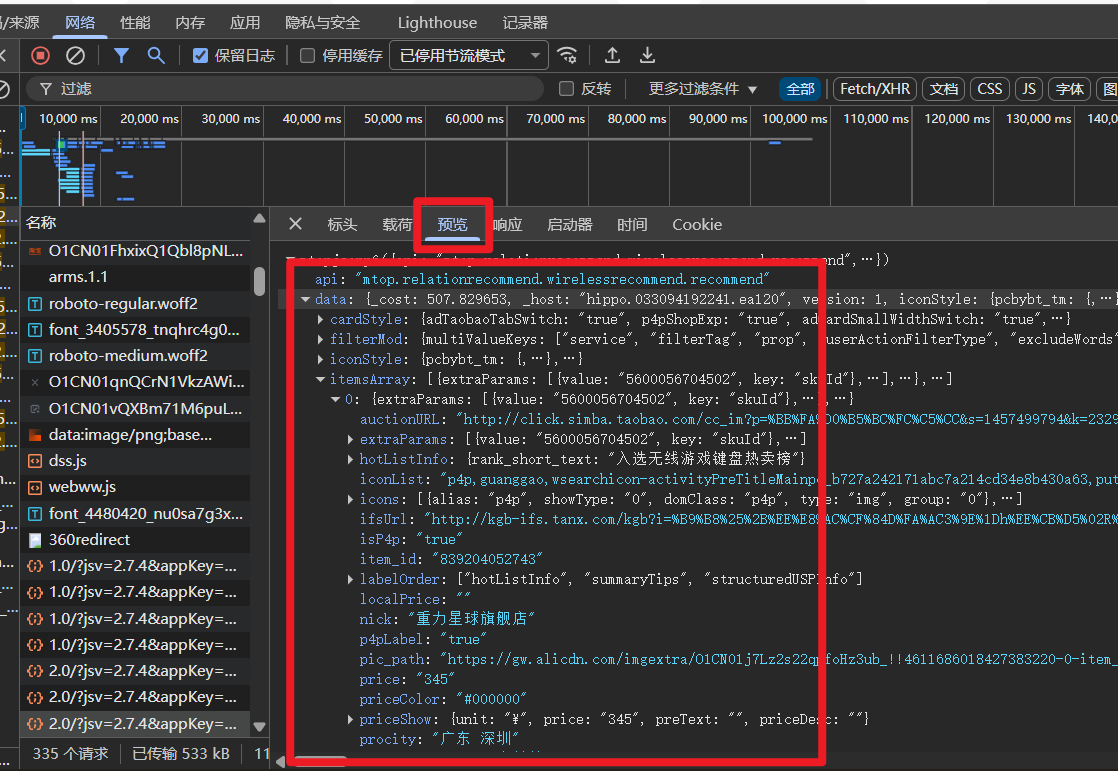
工具栏切换至 载荷 面板,经过多次数据包的抓取和分析可以发现,变化的参数存在三个:
t: 该参数表示时间戳sign: 加密参数data参数的q值:搜索内容编码
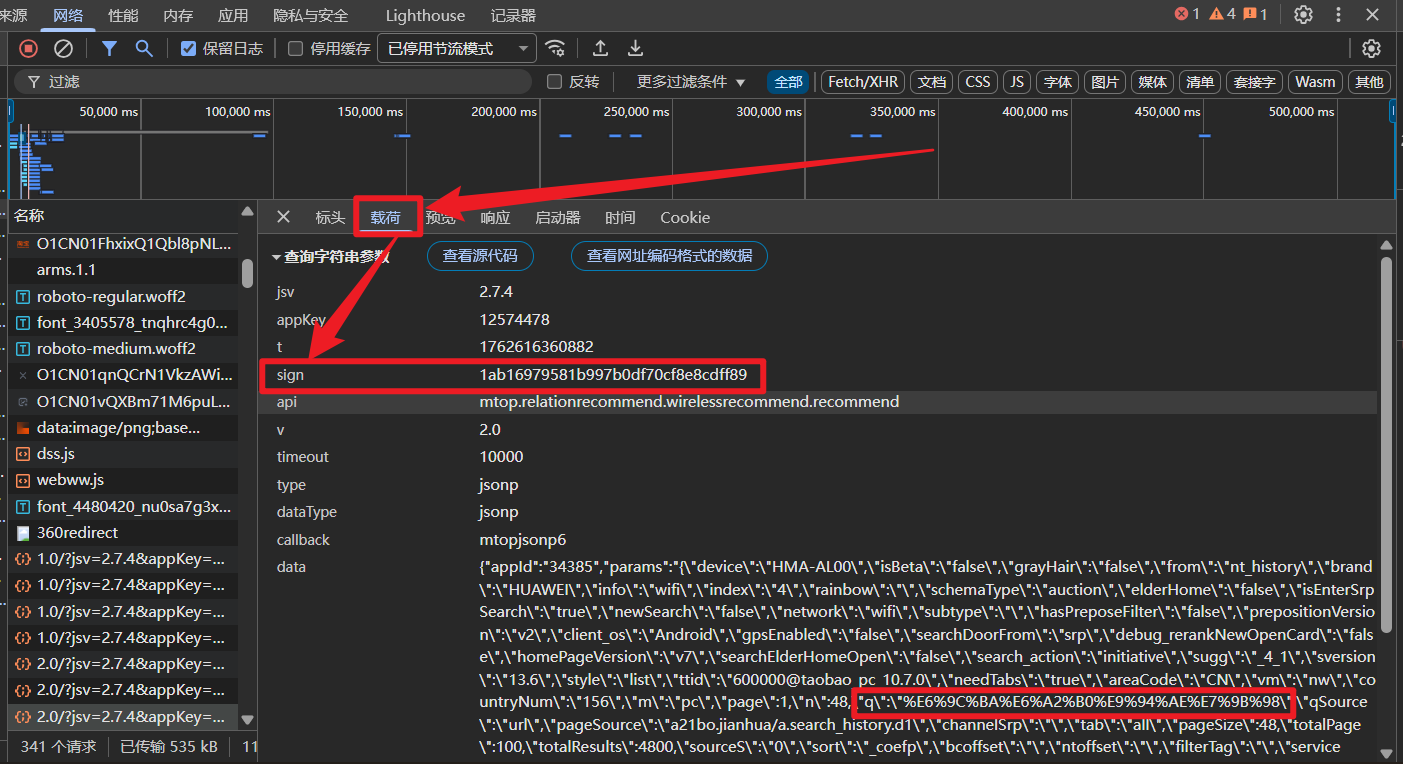
初步分析,时间戳 t 我可以使用 time 模块来解决,data 参数的q值我可以使用字符串拼接方式实现,问题就在与 sign 参数的生成。
进阶分析
接下来,需要对 sign 参数进行逆向分析它的生成方式。首先打开全局搜索,输入 sign: 进行搜素,在疑似生成目标参数的js代码片段前打上断点。然后再次执行搜索操作,程序将在断点处中断,通过调试分析发现,某个断点处包含 sign 的js代码片段中存在一个对 sign 进行赋值的操作,该js代码参考如下:
L{
jsv: 2.0.4,
cT: t,
sign: c
}
向上查找发现,变量 c 是由字符串拼接后作参数传入函数 eE 得到的,涉及字符串如下:
c = eE(em.token + "&" + eT + "&" + eC + "&" + ep.data)
将鼠标移动至这些拼接字符串的变量名上面,将弹出该变量的值,多次调试分析值后发现,存在一个 em.token 值,将该值复制后使用放大镜进行搜索发现,该值存在于 cookie 中,每隔一段时间将刷新一次,所以只需及时更换 cookie 即可;接着是 eT 变量,该变量的值刚好与载荷中的参数 t 相同;变量 eC 经过多次调试发现值是固定的;变量 ep.data 与载荷中的 data 参数相同。
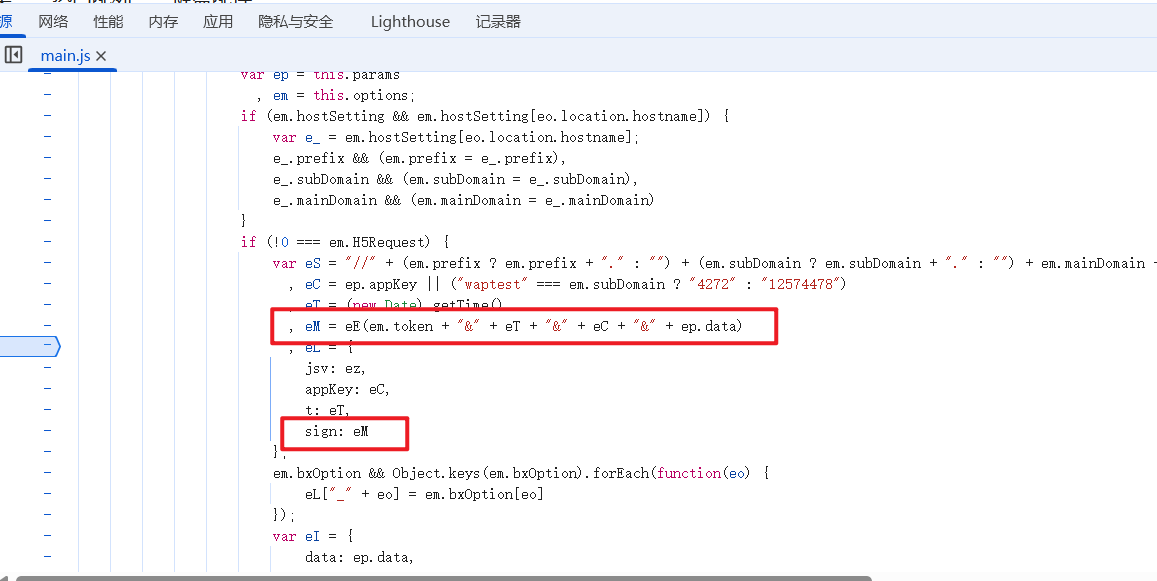
至此我们解决了 eE 函数传参问题,现在我们需要找到 eE 函数体。当程序处于断点调试状态时且断点到对 c 赋值部分的代码片段,可以通过将鼠标移动至 eE 函数上,将弹出该函数的原始函数体,点击后将跳转至函数体本身。
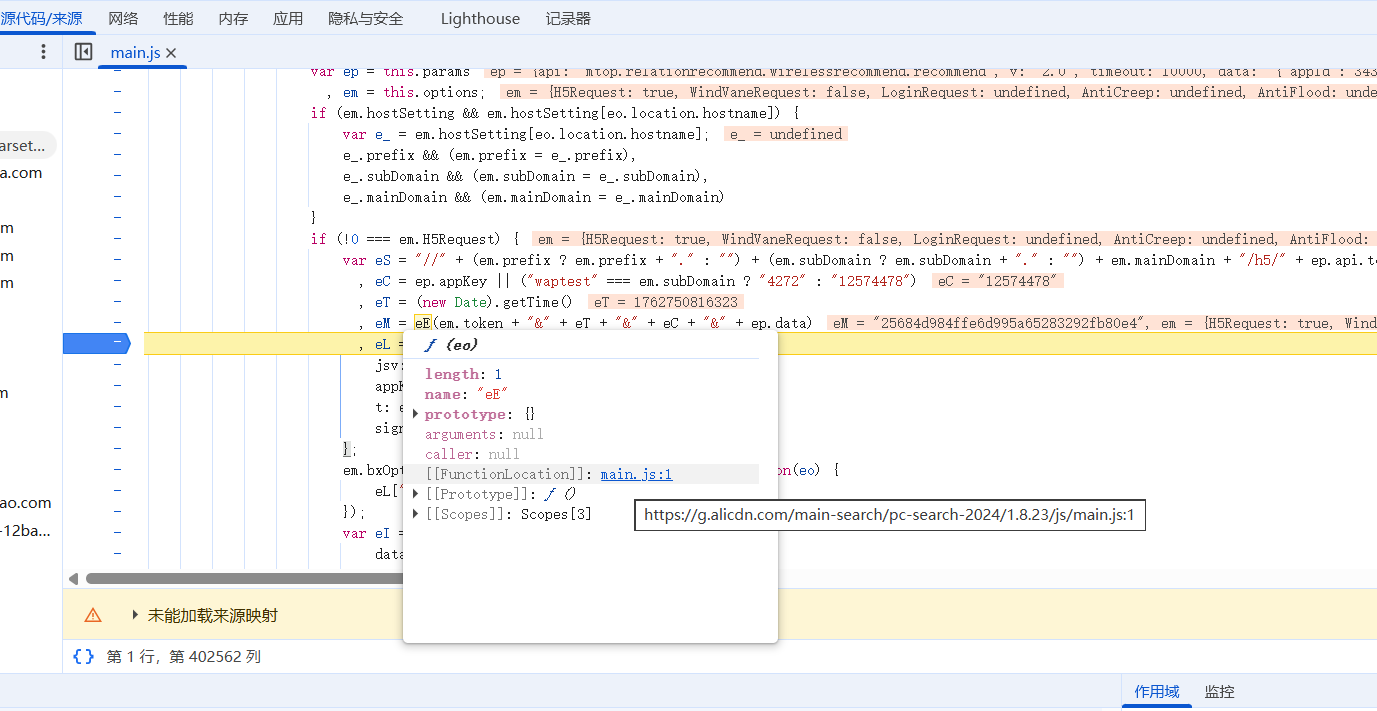
然后对该函数体进行复制,单独存入一个js文件中,然后在js文件中写入该函数所需的参数并进行调用调试,查看是否存在不完整情况,若成功得到加密后的 sign 值,则代表我们成功的找到了 sign 参数值的生成代码块。
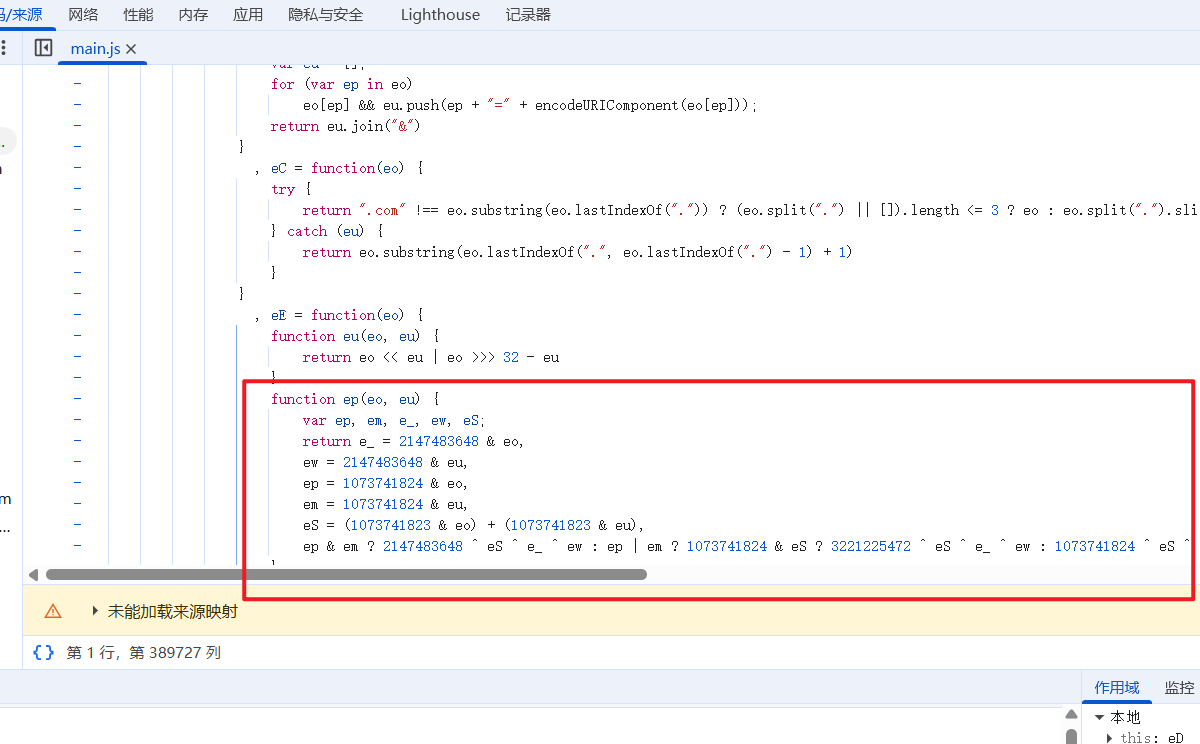
代码实现
分析了解完搜索部分的实现过程后,我们来设计代码,使用代码实现该功能。
代码整体架构
通过对目标网站的分析以及Requests的请求模块实现,对代码体进行简单构思:
- 确定请求方式
- 确定请求头和请求参数
- 发起请求得到响应体
- 对响应体中的数据进行提取
- 对提取到的数据进行保存
编写代码的整体框架:
class TaobaoSearch(object):
def __init__(self):
"""
初始化数据,定义用户输入
"""
def get_sign(self,t: str,data: str)->str:
"""
生成加密参数sign
:param t: 时间戳
:param data: 请求参数中的data
:return: 加密后的sign值
"""
def push_requests(self):
"""
发送请求,获取搜索数据
:return: response响应体
"""
def format_and_save_data(self,response):
"""
对传入的响应体数据进行处理
提取指定的数据内容
:param response: 响应体内容
:return: None
"""
def save_data(self):
"""
对提取到的数据进行本地化存储
:return: None
"""
整体框架搭建完成后,只需对其进行填空!
对象的初始化
在初始化方法 __init__ 中,需要对新的对象进行初始化,初始化的数据包含请求头、请求url、存储对象、时间戳、用户输入等内容,代码设计如下:
def __init__(self):
"""
初始化数据,定义用户输入
"""
# 定义初始url
self.basic_url = "https://h5api.m.taoba...2.0/"
# 设置请求头
self.headers = {
"Referer":"https://s.taobao.com/",
'User-Agent': fake_useragent.UserAgent().random,
# 此处淘宝的cookie需要及时更换,否则将显示(令牌过期)
'cookie':"thw=xx; cna=wN4DIV..."
}
# 定义时间戳
self.time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
# 创建excel
self.wb = workbook.Workbook()
# 获取当前正在操作的表对象 激活
self.ws = self.wb.active
# 设置表头
self.ws.append(['商品id','商品标题','商品价格',"店铺名称",'发货地址','销售量','图片链接','商品链接'])
# 获取用户搜索内容
self.params = input(f"\033[1;37m[{self.time}] Input 请输入你要获取的商品:\033[0m")
注意
在设计代码时请自行导入所需的模块
加密参数生成方法体设计
在该方法体中,我们需要模拟js代码中的 eE 函数体进行设计,首先设置字符串拼接所需的变量,依次有 em.token、eT、eC、ep.data等,其中 eT 和 ep.data 可以直接传入,因为在即将设计的请求方法体中存在;而 eC 可以采用硬编码方式;最后 em.token 可以在请求头中进行提取,至此,加密函数的实参构建完成。接下来使用 execjs 模块的使用方法调用js文件的函数体,获取 sign 的结果并返回。
# 获取加密参数
def get_sign(self,t: str,data: str)->str:
"""
生成加密参数sign
sign的组成:eE(em.token + "&" + eT + "&" + eC + "&" + ep.data)
:param t: 时间戳
:param data: 请求参数中的data
:return: 加密后的sign值
"""
# 从cookie中取出token
token = re.findall("_m_h5_tk=(.*?)_",self.headers['cookie'])[0]
eC = "12574478"
sign_str = token + "&" + t + "&" + eC + "&" + data
"""方法一:不知道加密方式时直接使用原始加密方式"""
with open("get_sign.js",'r') as f:
ctx = execjs.compile(f.read())
sign = ctx.call("eE",sign_str)
return sign
请求方法体设计
在请求方法体中对时间戳进行刷新,设置发送请求所需的params参数,将该参数的 data 元素单独提取出来,方便后续方法的使用,设置完成后就可以发起请求了,为发送请求进行异常处理。
# 发送请求
def get_url(self):
"""
发送请求,获取搜索数据
:return: response响应体
"""
# 生成时间戳
self.time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
t = str(int(time.time()*1000))
# 设置参数data
data = '"appId": "34385","params": {"ap...'+self.params+'..."sort": "_coefp"'
# 请求参数(requests的get请求参数params)
params = {
"jsv": "2.7.4",
"appKey": "12574478",
"t": t,
# 获取加密参数
"sign": self.get_sign(t, data),
"api": "mtop.rel...ommend",
"v": "2.0",
"type": "originaljson",
"timeout": "10000",
"dataType": "json",
"data": data
}
try:
response = requests.get(
self.basic_url,
headers=self.headers,
params=params,
timeout=10
)
return response
except Exception as e:
print(f"请求失败: {e}")
return 0
提取数据方法体设计
通过网页对数据包的预览结果分析,依次提取出商品所需的数据,为了让数据方便查看,我新增一个用于输出的 print_format 方法,在数据提取的同时依次添加数据到excel表,最后执行 self.wb.save("淘宝数据.xlsx") 命令进行本地磁盘的数据写入。所以此后框架中的save_data 方法作废,新增一个 print_format 方法。
# 提取数据
def format_and_save_data(self,response):
"""
对传入的响应体数据进行处理
提取指定的数据内容
:param response: 响应体内容
:return: None
"""
print(f"\033[1;32m[{self.time}] Success 正在提取数据...\033[0m")
html_str = response.content.decode("utf-8")
html_json = json.loads(html_str)
productInfo = html_json['data']['itemsArray']
for item in productInfo:
try:
pic_path = item['pic_path'] # 图片链接
shop_name = item['shopInfo']['title'] # 店铺名称
item_id = item['item_id'] # 商品id
local = item['procity'] # 发货地址
count = item['realSales'] # 已购人数
title = item['title'] # 商品标题
title = re.sub(r'<(.*?)>',' ', title)
price = item['price'] # 商品价格
item_url = item['auctionURL'] # 商品链接
if item_url[:2] == '//': item_url = 'https:' + item_url
self.print_format([item_id,title,price,shop_name,local,count,pic_path,item_url])
# 添加数据到excel表,数据列表与表头一一对应 此代码并非实际写入磁盘
self.ws.append([item_id,title,price,shop_name,local,count,pic_path,item_url])
except Exception as e:
pass
self.wb.save("淘宝数据.xlsx")
print("数据采集成功,已存入文件 -> 淘宝数据.xlsx")
格式化输出方法体设计
格式化输出的方法体将接收一个包含8个元素的列表,然后依次对该类表数据进行展示,代码如下:
# 格式化输出
def print_format(self,lis):
"""
格式化输出
:param lis: 商品元素列表
:return: None
"""
print('-'*70)
print(f'商 品 id: \033[1;32m{lis[0]}\033[0m')
print(f'商品标题: \033[1;37m{lis[1]}\033[0m')
print(f'商品价格: \033[1;32m{lis[2]}\033[0m')
print(f'店铺名称: \033[1;33m{lis[3]}\033[0m')
print(f'发货地址: \033[1;36m{lis[4]}\033[0m')
print(f'销 售 量: \033[1;35m{lis[5]}\033[0m')
print(f'图片链接: {lis[6]}')
print(f'商品链接: {lis[7]}')
实例化对象
实例化对象不用多说,就是构建一个对象,然后对该对象的方法进行调用。
if __name__ == '__main__':
tb = TaobaoSearch()
tb.format_and_save_data(tb.push_requests())
报错调试及处理
上述代码是我的首版代码,满怀激动的点击执行按钮,结果…
[2025-11-09 12:24:33] Input 请输入你要获取的商品:键盘
[2025-11-09 12:24:40] Success 正在提取数据...
Traceback (most recent call last):
File "D:\CodeFile\Program_Code\CrawlDemo\淘宝搜索\TaobaoSearch.py", line 167, in <module>
tb.format_and_save_data(tb.push_requests())
~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^
File "D:\CodeFile\Program_Code\CrawlDemo\淘宝搜索\TaobaoSearch.py", line 127, in format_and_save_data
productInfo = html_json['data']['itemsArray']
~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^
KeyError: 'itemsArray'
将代码的响应体进行打印发现,我获取到的数据长这样…
{"api":"mtop.relationrecommend.wirelessrecommend.recommend","data":{},"ret":["FAIL_SYS_TOKEN_EXOIRED::令牌过期"],"traceId":"2147bf7b17626624457367112e11b6","v":"2.0"}
我都没有获取到数据就对数据进行提取,不报错才怪。人在无语是确实会笑。但是为什么会获取不到数据呢?报错内容中显示 令牌过期,难道是我的 cookie 出了问题,对cookie进行更新后,满怀期待的重新点击执行…
[2025-11-09 12:37:20] Input 请输入你要获取的商品:机械键盘
[2025-11-09 12:37:26] Success 正在提取数据...
Traceback (most recent call last):
File "D:\CodeFile\Program_Code\CrawlDemo\淘宝搜索\TaobaoSearch.py", line 152, in <module>
tb.format_and_save_data(tb.push_requests())
~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^
File "D:\CodeFile\Program_Code\CrawlDemo\淘宝搜索\TaobaoSearch.py", line 112, in format_and_save_data
productInfo = html_json['data']['itemsArray']
~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^
KeyError: 'itemsArray'
再次将响应体进行打印发现,我的新数据包是这样的…
{"api":"mtop.relationrecommend.wirelessrecommend.recommend","data":{},"ret":["FAIL_BIZ_PARAM_ERR::valid appId([0]) Failed."],"traceId":"2147875917626630447182816e1167","v":"2.0"}
我将结果和情景丢给AI,让它帮我分析。

以下是AI给出的问题分析:
问题分析
从错误信息看,服务端返回的appId是[0],这说明:
- appId参数没有正确传递到服务端
- 参数格式或编码可能有问题
- 可能需要其他必需的参数
解决办法
- 更新cookie
- 原始代码中params字段JSON字符串转换为一个嵌套的对象结构
- 尝试重新分析参数
我对 cookie 进行更新且对参数进行增添后发现,结果任然报错,看来问题就出在了 data 格式或编码,AI给了我一个解决方案:
# 原始的data参数的构建
data = '"appId": "34385","params": {"ap...'+self.params+'..."sort": "_coefp"'
# 更新后的data参数构建
data_dict = {
"appId": "34385",
"params": json.dumps({
"appId": "34385",
...
"q": self.params,
...
"sort": "_coefp"
}, ensure_ascii=False, separators=(',', ':'))
}
data = json.dumps(data_dict, ensure_ascii=False, separators=(',', ':'))
对源代码进行修改后,再次执行!
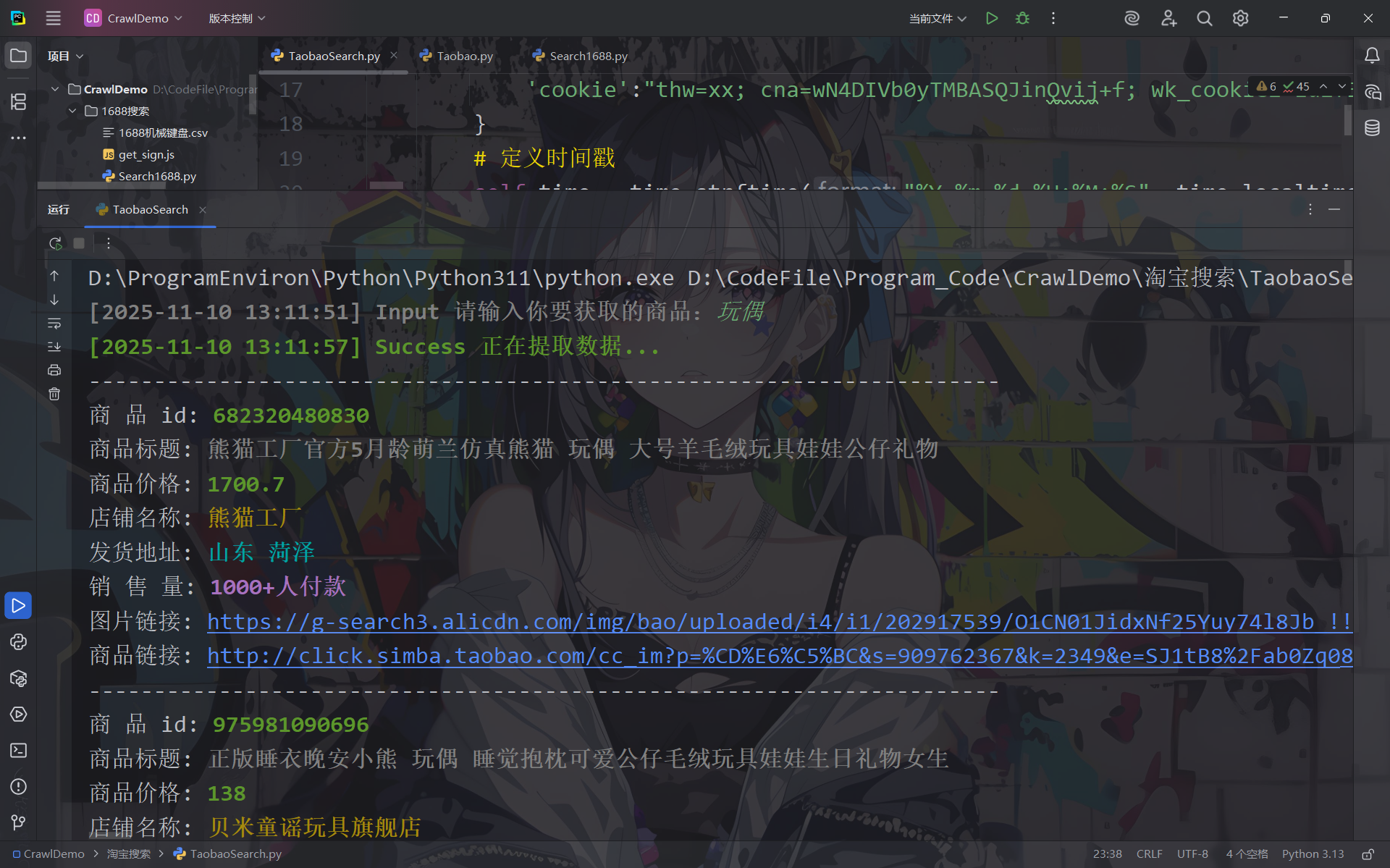
功夫不负有心人,终于得偿所愿的获取到了商品数据!这次的数据采集,让我学习了 sign 参数的js逆向,学会了使用 execjs 模块知识来保存采集到的数据,心中成就感满满!
